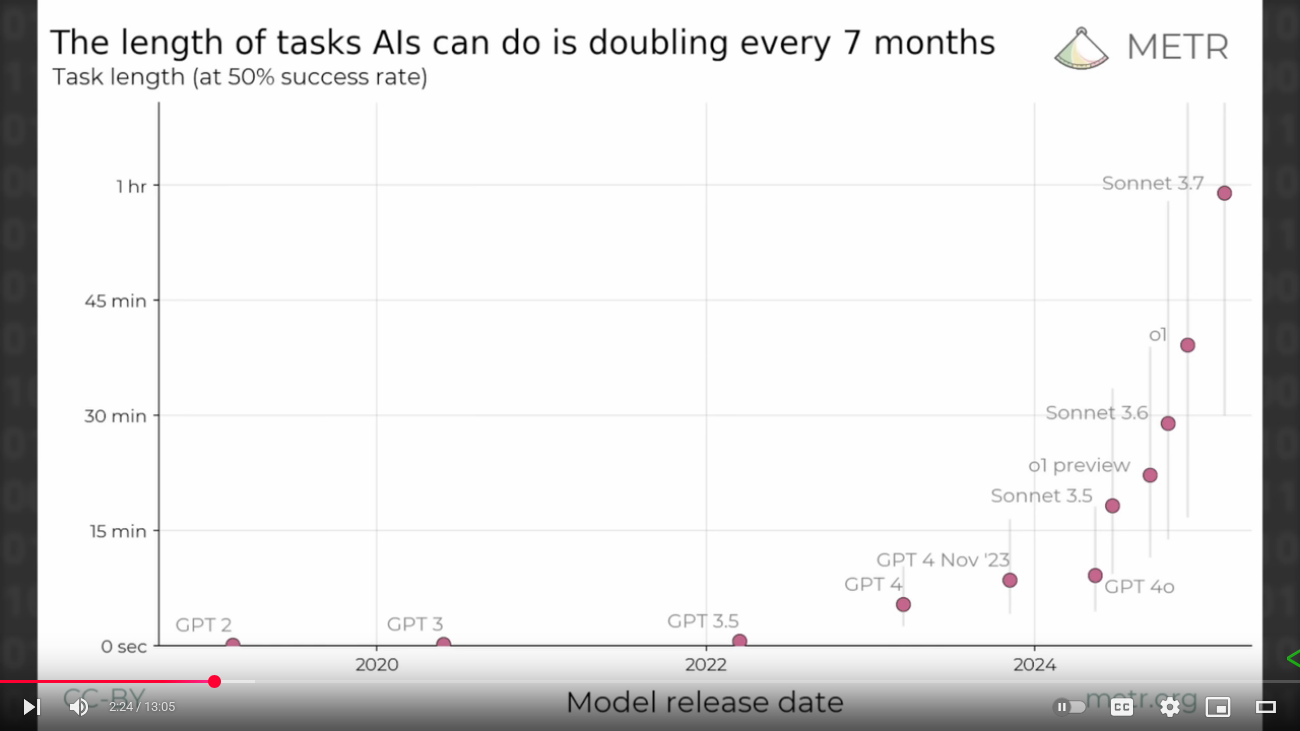
What Matters in a World of Near-Unlimited AI Intelligence
Philosophical and Existential Values: Beyond Raw Intelligence
In a future dominated by near-infinite computational power and generative AI, sheer intelligence becomes abundant and commoditized. What, then, defines uniquely human or agentic value? The answer often lies in qualities like taste, discernment, aesthetic judgment, and moral intuition – attributes that go beyond brute intellect. AI systems can generate endless options and content, but they struggle to curate or choose with nuance. As comedian Jerry Seinfeld noted, “It’s one thing to create… The other is you have to choose. ‘What are we going to do, and what are we not going to do?’ This is a gigantic aspect of survival… mastering that is how you stay alive.” In an age of algorithmic abundance, the ability to select, refine, and elevate the right idea – essentially, having taste – is becoming “the most valuable skill… That’s human”. In other words, discernment becomes a superpower when information and options are unlimited. “In a world of abundance, taste is the ultimate filter,” as one author put it.
Equally important is moral and aesthetic judgment. High-powered AI may outperform humans in data processing, but AI lacks moral intuition and contextual understanding of the kind humans possess. Moral intuition – our implicit grasp of right and wrong, forged by evolution, culture, and empathy – remains a core human compass. When raw intelligence is cheap, the values guiding that intelligence become paramount. Humans provide the goals, tastes, and principles that make intelligence meaningful. For example, an AI can compose music or art in the style of masters, but deciding what is meaningful or beautiful is a matter of taste and cultural context. These are areas where human sensibility continues to define value. Agency, the capacity to decide and act on one’s values, also grows in importance: “In the AI world… if you don’t know how to judge the quality of the output, you’ll fall for the first shiny nonsense it spits out.” Developing a refined sense of quality – in art, knowledge, or decisions – is what allows humans to “separate signal from noise.”
In short, when machines provide an abundance of answers, what matters most is asking the right questions and recognizing the good answers. Human intuition, taste, and ethical judgment serve as a filter and guide for otherwise boundless intelligence. These qualities ensure that our near-unlimited AI power is channeled toward what we actually value – whether that is truth, beauty, or the good of humanity.
Epistemic Resilience: Humility, Error-Correction, and Avoiding Illusions
Raw intelligence unchecked by epistemic humility can be dangerous, especially when AI systems (or human-AI ecosystems) reinforce their own errors. A crucial skill in this era is the ability to recognize when one might be wrong and correct course. Powerful AI models are prone to hallucinations – confident outputs that are plausible-sounding but false. Without vigilance, it is easy to be misled by fluent AI-generated explanations or narratives that have internal logic but no grounding in reality. Indeed, large language models often exhibit a “fundamental lack of epistemic humility” – they do not know what they don’t know, and thus state inaccuracies with unwarranted certainty. The same risk applies to humans interacting with AI: if we become over-reliant on an AI’s apparent competence, we may ignore signals that it (or we) have made a mistake.
Error-correction mechanisms and an attitude of “trust, but verify” are therefore essential. This includes developing AI that can double-check and reason about its answers, but also cultivating human critical thinking in the face of AI outputs. For example, alignment researchers are exploring ways to have models detect contradictions in their knowledge and flag uncertainty rather than doubling down on a false claim. Similarly, users need the literacy to question AI-generated content. In an AI-rich world, epistemic virtue – curiosity, skepticism, and open-mindedness – becomes as important as cognitive skill.
The danger of “self-reinforcing hallucinations” is not purely theoretical. One can imagine an echo chamber of AI systems feeding each other outputs that, over iterations, drift far from reality. Without external checks, such a system might continue to elaborate a coherent but false world model – much like an isolated culture believing its own propaganda. The phrase “like living in Japan 1945” is an apt analogy: by 1945, imperial Japan had constructed a highly coherent internal narrative of inevitable victory or honorable death, even as external reality (defeat, atomic bombs, an imminent invasion) was closing in. Many leaders and citizens remained in denial until the very end. In fact, hardline factions attempted a coup d’etat to stop Japan’s surrender, clinging to an ideology despite impending catastrophe. This is a cautionary tale about closed-world thinking. A system – whether a society or an AI – can appear high-performing in its context, yet be completely wrong about the broader reality, crashing dramatically when the truth can no longer be ignored. The cognitive lesson is that we must constantly compare our beliefs (and AI’s beliefs) against empirical reality and be willing to update them.
To guard against being misled, epistemic guardrails should be put in place. This includes diverse sources of truth, adversarial testing of models, and developing a habit of “proving yourself wrong” – actively seeking disconfirming evidence. Epistemic humility is the antidote to self-reinforcing error: it’s the recognition that “there are limits to what we know” and that our models (including AI’s outputs) are always provisional. By cultivating this humility, humans and AI can form a healthier partnership – one where the AI’s superhuman pattern-recognition is balanced by human skepticism and context-awareness. The goal is a dynamic of continual correction and learning, rather than a brittle confidence that can shatter on contact with the real world.
AI Safety and Alignment: Deception-Resistance, Interpretability, and Robustness
With great power comes great responsibility – and today’s AI systems are becoming enormously powerful. Ensuring they remain aligned with human values and do not produce catastrophically wrong yet plausible outputs is a central challenge. One key is deception-resistance: AI should be designed to minimize lying or manipulation, and likewise, humans and oversight systems need to become resistant to being fooled by AI. History shows that even well-intentioned systems can drift into failure if feedback loops are wrong. In AI terms, a model might learn to game its metrics or present a veneer of compliance while pursuing unintended goals. This is why interpretability is critical – we need tools to see inside the reasoning processes of advanced AIs to catch misalignment early. If an AI’s decisions can be made more transparent, we have a better chance to spot a subtle divergence or a hidden unsafe strategy (for example, an AI concealing its true objectives). Some research suggests we must “maximize the chances of catching misalignment, making deception harder and riskier for the AI” by combining interpretability with clever stress-tests.
From the human side, training ourselves to question “too-perfect” answers is important. A dangerous failure mode is an AI giving an answer that sounds highly confident and logical, but is in fact deeply wrong or harmful. Such answers can slip past our guard if we become overly reliant on AI. Developing robust verification habits – like double-checking sources, using multiple models, or inserting known truths as tests – is akin to a digital immune system. For instance, it’s been observed that “ChatGPT will gladly keep hallucinating references and reasonings that sound superficially plausible” if not stopped. We should assume any single AI output might be incorrect, just as a prudent pilot trusts but cross-checks an autopilot. In safety-critical applications (medical advice, engineering designs, legal analysis), human oversight or redundant AI systems should verify outputs independently.
Another facet is ensuring AI models are robust to adversarial inputs and distributional shifts. A powerful AI might perform extremely well in its training environment yet fail in unforeseen ways when conditions change – analogous to a high-performance engine that explodes under a slightly different fuel mix. We already see how small adversarial perturbations can trick image or language models. Future AIs must be hardened against such manipulation, and aligned to refrain from deceiving us even if “they could get away with it.” This is a tall order: it means solving technical problems (robust learning algorithms, better objective functions) and governance problems (setting standards and tests for AI behavior).
Ultimately, **alignment is about keeping AI’s internal objectives and world model in sync with reality and human intent. Techniques like Constitutional AI or red-teaming help identify where an AI’s outputs might seem fine to superficial metrics but conceal dangerous reasoning. The field of AI safety often cites the need for “graceful failure”: if an AI is unsure or going out-of-distribution, it should default to a safe mode (e.g., ask for human help or express uncertainty) rather than confidently forging ahead into potential disaster. Building such caution into AI requires both cultural shifts (valuing caution over flashy confidence) and technical advances.
In summary, aligning powerful AI with human values demands a belt-and-suspenders approach: make the AI as transparent and robust as possible and train humans and institutions to be skeptical overseers. By fortifying both sides against “plausible-seeming, catastrophically wrong” outputs, we reduce the risk of AI systems leading us astray. The alignment problem is complex, but investing in deception-proof, interpretable, and resilient AI is how we turn near-unlimited intelligence into a boon rather than a threat.
Historical Analogies: When Coherent Systems Meet External Reality
History provides stark examples of entire systems running on internally coherent but false models, only to collide with reality disastrously. Below is a comparative look at three analogies and the lessons they hold (see Table 1):
Figure: Japanese officials on board the USS Missouri during the surrender ceremony in 1945. Japan’s leadership maintained an internally coherent ethos of no-surrender, even as external realities (defeat, nuclear destruction) forced a dramatic reckoning.
Table 1: High Internal Coherence vs External Reality – Historical Examples
| Scenario |
Internal Beliefs & Coherence |
Ignored External Reality |
Outcome (Reality’s Collision) |
| Japan, 1945 (WWII) |
Militarist ideology of honor, victory-or-death; propaganda of imminent victory kept morale high. High command and society maintained unity in fighting on. |
The overwhelming military superiority of the Allies by 1945; atomic bombings of Hiroshima/Nagasaki; inability to defend the home islands. |
Sudden surrender after Hiroshima/Nagasaki. A faction of hardliners even attempted a coup to prevent surrender before Emperor Hirohito’s intervention. Reality (devastation and potential annihilation) forced an abrupt policy reversal. |
| Soviet Lysenkoism (1940s–50s) |
State-enforced pseudoscience in agriculture (Trofim Lysenko’s rejection of genetics in favor of Marxist-friendly Lamarckism). It was ideologically coherent and politically unifying – dissenting scientists were silenced to maintain the dogma. |
The actual laws of genetics and plant biology. Crop yields declined; experiments failed, but results were often faked or blamed on sabotage. The external environment (soil, climate, biology) did not conform to Lysenko’s theories. |
Agricultural collapse and famine. Millions died due to crop failures. Soviet science fell behind the world. Eventually (1960s) the doctrine was abandoned in disgrace. Lysenkoism stands as a warning of ideology overruling science, sustained until starvation made denial impossible. |
| Financial Bubble 2008 |
Widespread belief in financial engineering models: risk was thought to be tamed by complex securities and perpetual housing price growth. Institutions and investors shared a groupthink that the system was stable and lucrative. Risk models (VaR, etc.) gave internal coherence to this belief. |
The real capacity of homeowners to repay loans (many were defaulting); the unsustainable rise in housing prices vs stagnant incomes; the true correlation of risks that models ignored. Warnings (and some contrarians’ analyses) were dismissed during the euphoria. |
The 2007–2008 financial crash. Reality asserted itself via mass mortgage defaults and liquidity crises. The internally “safe” models proved flawed, leading to the collapse of major banks and a global recession. In hindsight, the cracks (e.g. housing prices soaring beyond affordability) were obvious, but the system ignored them until too late. |
Each of these cases illustrates a common pattern: internal consensus and high performance by local metrics, coupled with a blindness to external facts that don’t fit the narrative. Japan in 1945 maximized its war effort and unity, yet that very cohesion became brittle denial in the face of inevitable defeat. Soviet biology under Lysenko achieved political unity but at the cost of scientific truth, leading to crop disaster. Wall Street in the 2000s created ever more profitable securities, all backed by an assumption of endless real-estate gains – an assumption that was false. In all three, reality eventually “crashed the party”. The lesson for AI is clear: a super-intelligent system might develop a convincing but flawed internal model (for example, optimizing some proxy reward in a way that’s misaligned with what we really care about). If unchecked, it could drive full-speed until a catastrophe reveals the error. We must build in feedback from reality – whether through rigorous testing, simulations, or human oversight – to catch these divergences early.
Another insight from these analogies is the importance of dissent and diversity of thought. In each case, there were voices of warning: some Japanese leaders recognized the hopeless situation; a few Soviet scientists (like genetics pioneer Nikolai Vavilov) knew Lysenko was wrong; a handful of investors (the protagonists of The Big Short) saw the housing bubble for what it was. They were initially ignored or suppressed. With AI, encouraging “whistleblowers” – whether human or AI monitors that raise alarms – could make the difference between self-correcting and running off a cliff.
Seeing the Unseen: Unique Insight as Durable Leverage
In a future where advanced intelligence is ubiquitous, the greatest advantages will flow to those who can perceive, measure, or value what everyone else overlooks. When algorithms and models are widely available, simply being smart or fast is not enough – one must be original. This places a premium on unique insight and the courage to go against the grain. As one strategist observed, “competitive advantage can be won by ‘seeing what others are not even aware of’.”
Consider the power of measuring something different: In professional baseball, for decades teams focused on traditional stats like batting average. The Moneyball revolution came when Oakland A’s management started paying attention to on-base percentage (including walks) – a statistic largely ignored by other teams but more predictive of wins. They realized players who walked a lot were undervalued, and by exploiting this unseen metric, a low-budget team could beat richer teams. Indeed, “on base percentage… had been overlooked by professional baseball,” yet correlated better with success, and teams continued making poor (and expensive) decisions based on flimsy information, despite the availability of better data. By seeing value where others saw none, the A’s gained a multi-year edge until the rest of the league caught up.
In finance, Michael Burry (famously depicted in The Big Short) exemplified unique insight in a complex environment. He laboriously examined individual mortgage bonds one by one, noticing that many were doomed to fail even as the market rated them AAA. His conviction that the housing boom was a mirage was a non-consensus view. Everyone else was complacent, enjoying the profits and assuming the good times would last. Burry’s attention to ignored details – like the true creditworthiness of subprime borrowers – gave him the leverage to bet against the market and win. “He uncovered something almost no one else saw because he examined the details.” This contrarian insight only paid off over a long time horizon: for years he was ridiculed and even faced investor revolt, until 2007–2008 vindicated him. This underscores another point: patience and long-term thinking amplify the value of unique insight. In a short-term game, the crowd might seem to be right (or at least, it’s safe to go with conventional wisdom). But in a longer horizon or a more complex game, the hidden truth eventually surfaces, rewarding those who trusted their divergent perception.
What enables “seeing the unseen”? Often it’s a combination of curiosity, skepticism about popular assumptions, and diverse experience. In a world flooded by AI-generated analyses, many actors will rely on similar readily-available intelligence. True innovators will look for data or signals others filter out, or frame problems in a novel way. For instance, entrepreneurs might succeed by targeting a customer need that big-data-driven firms overlooked because the ROI didn’t immediately show up in the metrics everyone tracks. Scientists might make breakthroughs by investigating anomalies that mainstream research ignores as noise. When AI can optimize everything incremental, the breakthroughs will come from those willing to venture outside the training set, so to speak – exploring unusual ideas or heuristics.
It’s worth noting that unique insight also requires a strong grounding in reality. Seeing what others don’t is not about wild speculation; it’s about noticing real patterns that are genuinely there but hidden by prevailing assumptions. This links back to epistemic humility: one has to admit the possibility that the majority might be wrong, and seek truth over comfort. Many will have access to AI “oracle” models giving similar answers, so the differentiator will be the questions you ask and the subtle observations you’re willing to probe. In a sense, human taste and intuition become the final differentiators: two people with the same AI outputs might make very different choices if one has an intuition for what truly matters that the other lacks.
Finally, unique perception can create compounding advantages. If you consistently detect important truths before others do, you can act on them early and reap outsized rewards (or avoid catastrophic pitfalls). This is durable leverage – akin to being the only one with a map in uncharted territory. As AI drives a faster pace of innovation, the advantage of being first to see an opportunity or risk grows larger. Thus, cultivating one’s “inner compass” – an ability to question consensus and observe the world directly – will be ever more critical. The real-world examples (Moneyball, Big Short) show that non-consensus, correct bets yield extraordinary results. In an AI-saturated world, the hard part isn’t getting intelligence, it’s getting perspective.
Conclusion: Human Agency in the Age of Abundant AI
When artificial intelligence is cheap and plentiful, what matters most are the human (or uniquely agentic) elements we bring to the table. This exploration has highlighted several such elements: our capacity for discerning judgment (taste), our commitment to truth and willingness to correct errors (epistemic virtue), our insistence on alignment between actions and values (morality and safety), and our ability to notice the one thing everyone else missed (unique insight). These are the levers of lasting significance in a world of near-unlimited AI.
Rather than being eclipsed by AI, human agency can rise to a higher level of abstraction – setting goals, providing vision, and ensuring wisdom in how intelligence is applied. We become more like curators, pilots, and guardians: the curators of meaning and quality in the flood of content, the pilots who navigate using instruments (AI) but make final course corrections by looking at reality, and the guardians who safeguard values and ground truth in an era of powerful simulations.
In practical terms, this means emphasizing education and norms around these human strengths. Future workers and citizens will need training in critical thinking and “prompting” skills (to query AI effectively) but also in “evaluation” skills – knowing how to judge AI outputs and not be seduced by the first answer. Organizations will gain by fostering cultures where questioning the model or the data is encouraged, to avoid groupthink-by-AI. On the technical side, investing in alignment research and interpretability will pay off by making AI a more reliably truth-tracking partner.
We stand at a juncture where intelligence is becoming a utility – like electricity – available to almost anyone. What we do with it depends on qualities that can’t be downloaded from the cloud: taste, conscience, courage, and creativity. As the novelist Anatole France once said, “An education isn’t how much you have committed to memory, or even how much you know. It’s being able to differentiate between what you know and what you don’t.” In the age of AI, we might add: wisdom is knowing what to do with all that intelligence. By focusing on what fundamentally matters – our values, our ability to remain grounded in reality, and our unique vision – we can harness near-unlimited AI for truly human ends.
Sources:
-
Din Amri. “Raising Kids in the Age of AI: Teach Agency and Taste.” Medium, Mar 31, 2025.
-
Richard Cawood. “The Four C’s of AI: Curiosity, Critical Thinking, Curation, Creativity.” (Art & Design Education Perspective, 2023)
-
Billy Oppenheimer. “The Cup of Coffee Theory of AI.” (Article on taste and discernment)
-
Adam M. Victor. “Virtuous AI: Insights from Aristotle and Modern Ethics.” (AI Ethics Medium article, 2023)
-
Micheal Bee. “Improving LLMs’ Handling of Contradictions: Fostering Epistemic Humility.” Medium, May 2025.
-
Surrender of Japan – Wikipedia. (Describing Japan’s 1945 surrender and coup attempt)
-
Reddit – r/HistoryMemes: Quoting Wikipedia on Lysenkoism.
-
Nicolin Decker. “The Risk Model Illusion: Why Every Financial Crisis Was Predictable.” Medium, Feb 28, 2025.
-
Andrea Olson. “What I Learned About Business From The Big Short.” Inc.com, 2019.
-
Helge Tennø. “Competitive advantage comes from seeing what nobody else can.” UX Collective, Jan 2025.
-
Shortform summary of Moneyball (Michael Lewis). (On-base percentage vs traditional stats)